3 major challenges (and solutions) to CI/CD for remote development teams
6 Oct 2021

Managing an effective CI/CD process is a challenge in normal conditions. Doing so across multiple timezones and locations comes with unique challenges. Distributed has worked to solve these challenges for our global client base and here are some of our learnings.
Engineering managers are living in a new remote-first reality.
For many, they were already partially there or had the systems in place to continue business as usual even while teams moved from offices to WFH. As a company that lives and breathes remote software development. We’ve been thinking about how we can add value to the engineering managers and departments beyond that of your typical “You can’t handle remote teams” article.
Here, we’ll set out the unique challenges remote teams face managing a CI/CD process. How Distributed is solving those challenges and why the solution is better than what existed before.
Improving not only software delivery speed and quality but also enhancing the ability of your digital roadmap to deal with stressors – like for instance, a global pandemic of epic proportions.
Distributed has been building solutions to these challenges for years.
Quick self-promotion; Distributed is an on-demand software development company. We source and manage specialist freelance developers and wrap entire expert teams into one hourly rate. We call them Elastic Teams™️.
It’s always been our goal to make it as simple as pushing a button for developers to get high-quality work and for companies to get the highest quality development outcomes.
Achieving our goal depends hugely on Scalability.
Taking on a new client means building a team around a set of highly specific and custom requirements as quickly as possible (typically less than 48 hours). We need to do that while managing potentially hundreds of projects at any one time.
Scaling up/down work on-demand is a challenge that is impacting many of our clients.
Raise your hands if you’re feeling either of the following:
You’ve had to layoff team members but had to continue delivering the digital roadmap.
Your roadmap has completely changed and now involves skillsets that you don’t have on the team.
A survey by AppDynamics[1] found, 64% of technologists are now being asked to perform activities they have never done before. 66% of technologists see that the pandemic has exposed weaknesses in their digital strategies, creating an urgent need to accelerate initiatives that were once part of multi-year digital transformation programs.
So the pressure to scale up work and down costs has never been higher.
The critical challenges of scalability in a remote CI/CD setting
Contextual understanding of the project for every remote developer
Every developer needs to understand the big picture of what you’re developing to do their job efficiently. That onboarding time is an unavoidable part of the process.
But how do you then bring in new developers urgently and ramp up work quickly if every one of them needs time to get their head around the entire codebase?
Code review bottlenecks
Code review is a critical part of effective Continuous integration and deployment. Without a technical leader, reviewing each block of code before deploying, bugs and problems will quickly arise.
But how do you manage code review when you want to keep your core development team small, and focused on driving projects forward?
Quality assurance bottleneck
Acceptance testing also plays a massive role in an effective CI/CD process. Typically a QA lead will conduct the unit and functional tests to approve a block into a production environment.
But what if your QA lead is working on other projects or in different timezones, it could be days before a block is going live.
The Distributed Process
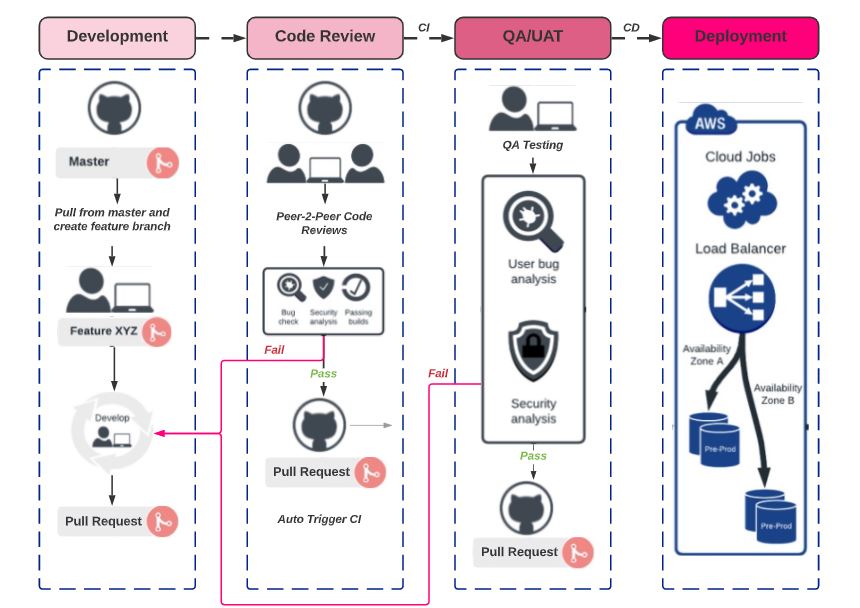
(Fig 1. Distributed’s CI/CD process)
Challenge #1 – Contextual understanding
Context is an immense blocker for Distributed Elastic Teams™️. A blocker that is facing many teams with new software challenges they don’t have the skillsets for. That meets any company trying to outsource any part of their software development. Particularly if you’ve got an old undocumented, complicated codebase that breaks anytime you release a new feature.
In a local office environment getting teams together and maintaining context would be easy. But with team members all over the world in multiple timezones, any change by one developer can mean a loss of context and code being overwritten for another.
Solution #1 – Heavy componentisation and documentation of repeatable features
We reviewed 100s of past projects and found that 65% of all project features we had delivered could be broken down into repeatable components.
For example, a “Login” feature can be broken down into components of authorisation & authentication. Individually those components will be primarily the same across many projects.
Instead of having one or two developers tied to each project, the technical lead can produce a continuous stream of components that any Elastic Team member can pick up and work on.
The context needed to work in this manner is heavily reduced and improves:
The speed of delivery cutting onboarding time
The quality as all our components are documented and reiterated to improve over time (the more projects we run the better and more streamlined each component becomes)
The ability to deal with stressors as if one developer isn’t available (for example because of sickness) another developer can pick up the ticket and develop the code.
Challenge #2 – Code review
Code review is a considerable challenge for businesses with only one technical lead to review and approve code. In a local office environment meeting with the technical leader could be quick and easy but again across multiple timezones, it could take hours or days to review code. This wastes the developer’s time as they can be waiting for feedback instead of moving on with other task tickets.
Solution #2 – Use our Elastic Team™️ talent pool to peer review code
We’re quite lucky to have unfettered access to >350 expert developers covering any kind of specialist frameworks and languages. Our Elastic Team™️ members (ETMs) have an average of 11 years of senior programming experience. At the same time, our technical leads are not necessarily expert in every language. Through peer review, we remove the technical lead as the bottleneck between code being approved and pushed into the testing environment.
Given the scale-up and down nature of our workload this also helps to utilise downtime for ETMs. In the case of projects where dependencies exist, an ETM waiting for another ticket to complete can jump into peer review. Providing further context to that ETM on the project and allowing even more efficient onboarding to that project in the future.
Not every company has an instantly accessible pool of expert developers at their beck and call. But the learning to be taken here is to utilise talent networks. Engage on-demand talent sooner in the SDLC to establish relationships. Then when you do need them to jump in to help review code, they can be ready to do so.
Challenge #3 – Quality Assurance
Very similarly to code review, typically one person or team is responsible for QA in the business. With limited capacity, we need to ensure that projects don’t get blocked at this late and crucially important stage.
According to a survey from GitHub, 47% of companies said that project delays were due to problems with testing.
After QA, the client will see our work and so any bugs must be caught, for us to deliver on our highest quality outcome promise.
Solution #3 – Leverage the ETMs and document repeatable tests for each component.
The better job for our core QA team lead is to be working closely with the technical lead in the componentisation of features to build out repeatable tests for each component.
We are creating a huge database of functional tests structured into lists of tasks to fully test each component. Meaning again that many of our ETMs are qualified to pick up and complete. This means problems can be identified quickly, without context and highly efficiently. Once a problem has been found a ticket can be created and pushed back into the development workstream. All without the QA lead having to be involved.
The key again is to engage flexible on-demand talent networks that can fulfil the requirements of the tasks.
What does a distributed future of work look like
We’ve learnt through +100 client engagements that componentisation, documentation and agile talent networks really do work to improve quality and speed to an outcome. According to recent research by US company Constellation[2], 72% of corporations were running dynamic and elastic teams; a big leap from research two years earlier, when just 52% used such methods. Those respondents reported a 30% higher cost efficiency, 60% lower risk of failure and 3.6x higher satisfaction with the outcome than those that were not using dynamic teams.
We’re now learning due to the pandemic that it also pays to be antifragile by design. The inherent fragility of local teams in a crisis such as this has been fully exposed.
Normal workstreams are localised, for a single business, working on only a handful of projects and an even smaller amount of features at any one time. This is fragile as it only takes a single person to leave the business or be unavailable for work to stall.
The future workstream is global, working for many businesses, on many projects and across many different features all broken down into smaller component parts. That is an antifragile by design future. That improves from disorder and stressors rather than breaks from it.
